
日本語対応の全文検索プラグインです。
目次 [閉じる]
説明
WordPress のサイト内検索 (ワード検索) を、LIKE 検索から日本語対応の全文検索 (MySQL + Ngram または Mroonga + Mecab) に置き換えます。これにより検索のパフォーマンスが大幅に向上します。
WordPress 標準の検索は、投稿の表示内容ではなく編集データを検索します。よって、HTML タグやショートコードのコードなどが検索されてしまいます。全文検索では、HTML を除いた純粋な文字列 (プレーンテキスト) で検索します。また、ショートコードやパターンブロックを展開した内容でも検索することができます。
検索用のデータ (インデックス) は、専用のテーブルに保存されます。既存のテーブル構造や投稿データ (posts テーブル) を書き換えることはありません。
PDF (自動テキスト抽出機能はβ版扱い)、Word (doc、docx)、Excel (xlsx) および PowerPoint (pptx) ファイルのテキストを検索します。
WordPress マルチサイトに対応しています。
外部サービスを一切使用していません。投稿データや PDF ファイルなどを外部のサーバーへ送信することはありません。
使い方
プラグインを有効化するだけで、標準のワード検索が全文検索になります。設定画面で全文検索の無効化、検索ページのみ有効化などが設定できます。
全文検索メンテナンス (管理画面メニューより [設定]-[全文検索]-[メンテナンス] タブ) より、全文検索インデックスをメンテナンスすることができます。通常の運用では操作することはありません。データベースの投稿データを直接変更した場合に、投稿データとインデックスの不整合が起きた場合に操作します。
「full_text_search_search_text」という名前のカスタムフィールドを作成すると、その値 (テキスト) も検索対象となります。
検索文字列オプション
下記のような Google ライクの検索オプション (演算子) が使えます。
OR(大文字) – 検索を結合します。例: foo OR bar-– 検索から語句を除外します。例: foo -bar""– 完全一致を検索します。例: “foo bar”*– ワイルドカードで検索します。Mroonga のみ。例: foo*()– グルーピングします。Mroonga のみ。例: (foo OR bar) baz
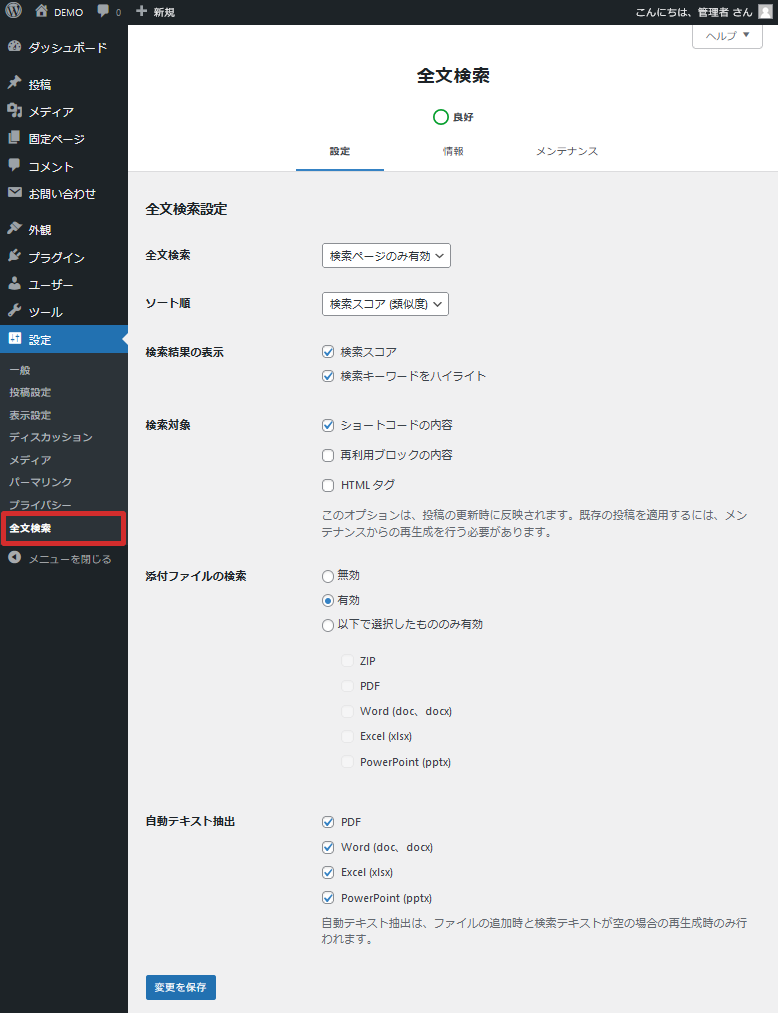
全文検索設定
全文検索の設定を行います。
設定項目
| 設定項目 | 説明 |
|---|---|
| 全文検索 | 全文検索の有効または無効を設定します。 「有効」はすべてのワード検索 (管理画面や WP_Query、get_posts() を含む) で全文検索が有効になります。「検索ページのみ有効」は検索ページのみで全文検索が有効になります。 初期値は「有効」です。 |
| ソート順 | ソート順 (デフォルトまたは検索スコア) を設定します。 「デフォルト」は WordPress のデフォルト(タイトル→投稿日) 順、「検索スコア (類似度)」は検索文字列とデータの類似度順となります。 初期値は「検索スコア (類似度)」です。 |
| 検索結果の表示 | 「検索スコア」 検索スコアを表示するかどうかを設定します。 検索スコアは抜粋の上部に表示されます。抜粋ではなくコンテンツを表示しているテーマの場合は表示されません。専用のタグ (Full_Text_Search::get_the_score()) をテンプレートに追加するか、functions.php にコードを追加する必要があります。 |
| 「検索キーワードをハイライト」 検索キーワードをハイライトするかどうかを設定します。 | |
| 「ハイライトに mark.js を使用する」 ハイライトに mark.js スクリプトを使用するかどうかを設定します。 | |
| 「検索結果の内容」 検索結果の内容を、コンテンツか抜粋かを選択します。テーマの検索テンプレートに合わせて選択してください。 | |
| 検索対象 | 「ショートコードの内容」 ショートコードの内容を検索するかどうかを設定します。 |
| 「同期パターンの内容」 (バージョン2.12.3以下は「再利用ブロックの内容」) 同期パターンの内容を検索するかどうかを設定します。 ※ 検索対象は、投稿の更新時およびインデックスの再生成時の同期パターンの内容となります。 | |
| 「HTML タグ」 HTML タグを検索するかどうかを設定します。 | |
| 添付ファイルの検索 | 添付ファイルの検索の有効または無効を設定します。 初期値は「有効」です。 |
| 自動テキスト抽出 | PDF および Word ファイルを追加時に自動でテキストを抽出するかどうかを設定します。 |
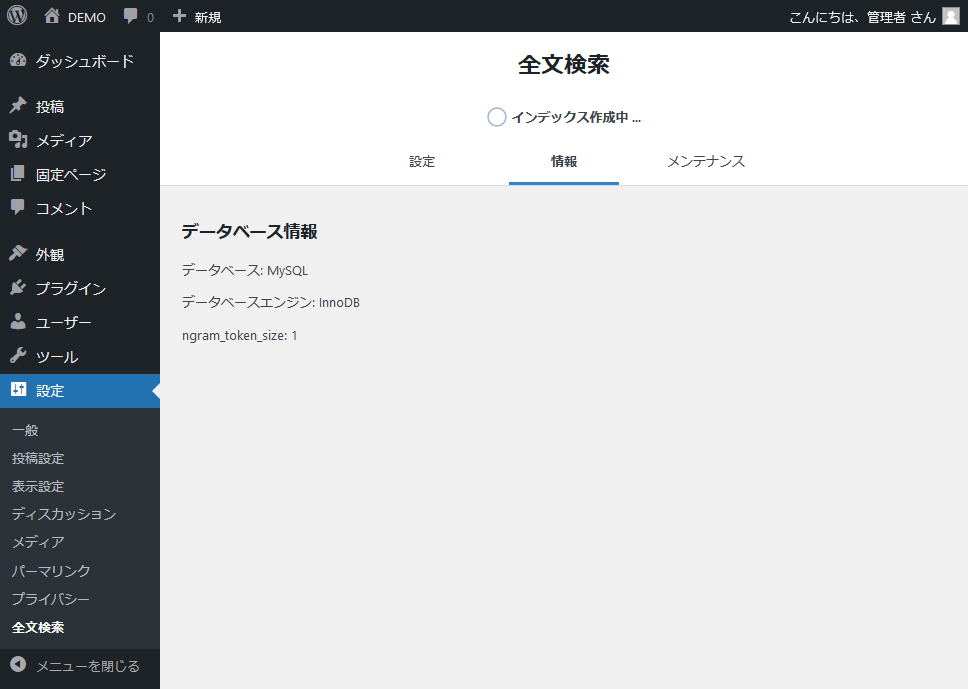
全文検索情報
データベース情報などが表示されます。
表示項目
| 表示項目 | 説明 |
|---|---|
| データベース | インデックスを作成しているデータベース (MySQL または MariaDB) を表示します。 |
| データベースエンジン | インデックスを作成しているデータベースエンジン (InnoDB または Mroonga) を表示します。 |
| ngram_token_size | ngram_token_size システム変数値を表示します。 ※ InnoDB エンジンの場合のみ表示されます。 |
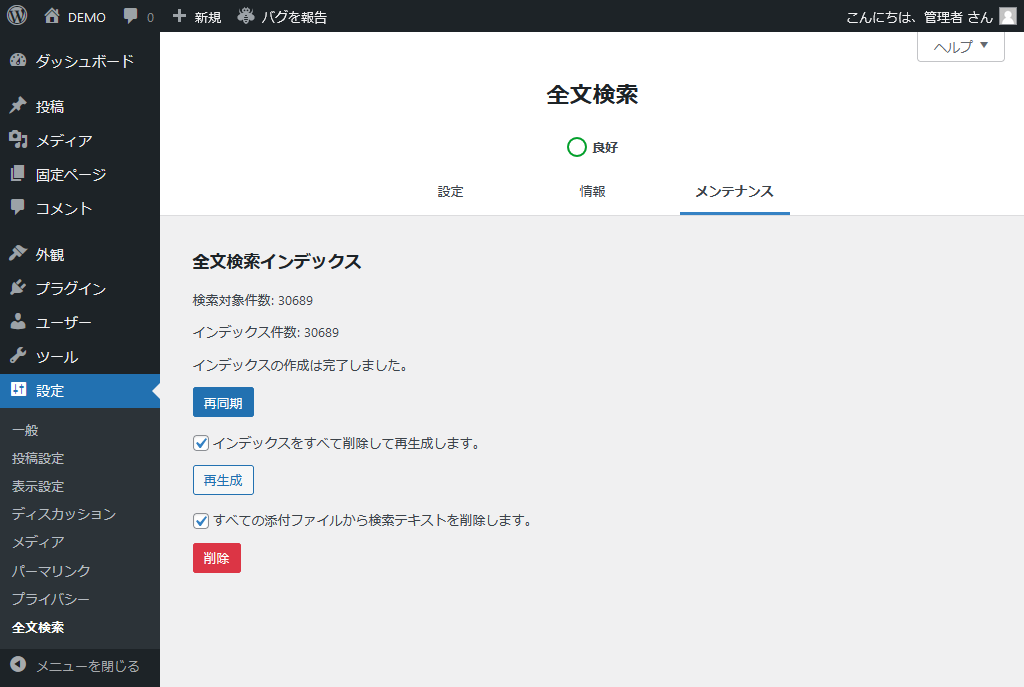
全文検索メンテナンス
全文検索のインデックスの再同期や再生成を行います。
設定項目
| 設定項目 | 説明 |
|---|---|
| 再同期 | インデックスを更新します。 |
| 再生成 | インデックスをすべて削除して再生成します。 |
| 削除 | すべての添付ファイルから検索テキストを一括削除します。 |
添付ファイルの詳細
検索対象のテキストを編集します。
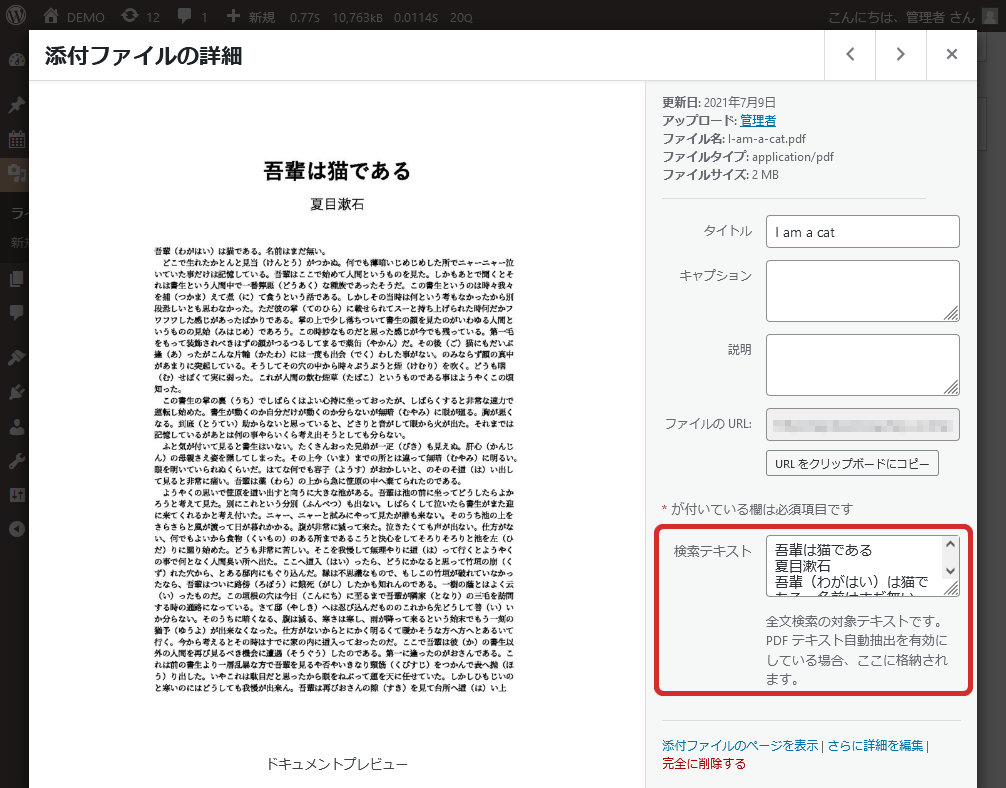
自動テキスト抽出を有効にしている場合、「検索テキスト」項目に抽出したテキストが格納されます。このテキストを変更した場合、インデックスの再生成で更新されることはありません。再生成する場合は空にしてください。
インストール
- WordPress 管理画面->[プラグイン]->[新規追加] メニューより、[プラグインを追加] ページを開きます。
- 検索ボックスに、”Full-text Search” と入力し検索します。
- Full-text Search が見つかったら、[今すぐインストール] をクリックします。
- インストールが完了したら “プラグインを有効化” をクリックします。
データベース設定
InnoDB エンジンの場合、ngram_token_size システム変数のデフォルト値は2で、この場合1文字での検索は効きません。現在値は、設定画面で確認することができます。
動作環境
- WordPress 5.5以上
- PHP 7.2以上
- MySQL 5.6以上または Mroonga エンジン+MeCab
注意事項
- Mroonga エンジンを強く推奨します。InnoDB エンジンでは、データ量が多い場合や ngram_token_size が1の場合などにパフォーマンスが大幅に低下することがあります。また、InnoDB では一部の短い単語(ストップワード)がヒットしない場合があります。
- Mroonga エンジンでは MeCab トークナイザーが必須となります。
- Mroonga エンジンが利用可能な場合は、InnoDB エンジンよりも Mroonga エンジンを優先して使用します。
- 投稿データを WordPress 経由ではなくデータベースを直に変更した場合は、再同期 (全文検索ツールより [再同期] ボタンを押下) する必要があります。投稿データの更新日を更新しないように書き換えた場合は、再生成 (全文検索ツールより [再生成] ボタンを押下) する必要があります。
- 保護された PDF ファイルのテキスト自動抽出には対応していません。
- データベース エンジンの異なる環境へ移行する場合、エクスポートする前に一旦プラグインを削除してからエクスポートしてください。移行プラグインによってはインポートに失敗する場合があります。
フック
- full_text_search_index_post
- full_text_search_pdf_text
- full_text_search_limit
- full_text_search_highlight_selectors
カスタマイズ
全文検索は標準のワード検索を置き換えます。そのため基本的には標準の WordPress のカスタマイズが有効です。絞り込み検索プラグインとも基本的には併用可能です。
検索ページの検索を添付ファイルのみに制限
検索ページの検索を添付ファイルのみに制限します。
function search_filter( $query ) {
if ( ! is_admin() && $query->is_main_query() ) {
if ( $query->is_search ) {
$query->set( 'post_type', 'attachment' );
}
}
}
add_action( 'pre_get_posts', 'search_filter' );カスタムフィールドの検索
特定のカスタムフィールド(サンプルでは「カスタムフィールド1」と「カスタムフィールド2」)を全文検索の対象に含めます。
add_filter( 'full_text_search_index_post', function( $data, $post_ID ) {
if ( 'post' === $data['post_type'] ) {
$text = $data['keywords'];
$text .= ' ' . get_post_meta( $post_ID, 'カスタムフィールド1', true );
$text .= ' ' . get_post_meta( $post_ID, 'カスタムフィールド2', true );
$data['keywords'] = trim( $text );
}
return $data;
}, 10, 2 );※ インデックスを再生成する必要があります。
検索データ項目は下記の4項目があります。違いは検索スコアの重みで keywords と post_title は若干高く重みづけされています(重みは Mroonga のみ有効)。
- keywords
- post_title
- post_content
- post_excerpt
ファイルブロックの検索
ファイルブロックで指定したファイルの内容を全文検索の対象に含めます。
add_filter( 'full_text_search_index_post', function( $data, $post_ID ) {
if ( 'post' === $data['post_type'] ) {
$text = $data['post_content'];
$blocks = parse_blocks( get_post_field( 'post_content', $post_ID ) );
foreach ( $blocks as $block ) {
if ( 'core/file' === $block['blockName'] ) {
$id = $block['attrs']['id'];
$text .= "\n" . get_post_meta( $id, 'full_text_search_search_text', true );
}
}
$data['post_content'] = trim( $text );
}
return $data;
}, 10, 2 );
※ インデックスを再生成する必要があります。
Download Manager プラグイン
Download Manager プラグインの投稿に添付された PDF ファイルのテキストを全文検索の対象とします。
下記コードは、Download Manager の投稿の保存(更新)時に PDF ファイルのテキストを抽出して full_text_search_search_text カスタム フィールドに保存しています。
add_action( 'wpdm_admin_update_package', function( $post_id, $post_files ) {
global $full_text_search;
if ( empty( $full_text_search ) || ! isset( $full_text_search->options['auto_pdf'] ) || ! $full_text_search->options['auto_pdf'] ) {
return;
}
if ( defined( 'UPLOAD_DIR' ) ) {
$dir = UPLOAD_DIR;
} else {
$upload_dir = wp_get_upload_dir();
$dir = $upload_dir['basedir'] . '/download-manager-files/';
}
$text = '';
foreach ( $post_files['files'] as $file ) {
$file = sanitize_file_name( $file );
$filename = $dir . $file;
if ( file_exists( $filename ) ) {
$ext = pathinfo( $filename, PATHINFO_EXTENSION );
if ( 'pdf' === strtolower( $ext ) ) {
$text .= $full_text_search->get_text_from_pdf_file( $filename ) . ' ';
}
}
}
$text = trim( $text );
update_post_meta( $post_id, 'full_text_search_search_text', $text );
}, 10, 2 ); ※ この機能を有効にするには、Full-Text Search プラグインの「自動テキスト抽出」設定で PDF を有効にする必要があります。
get_posts()
WP_Query や get_posts() からも全文検索で検索することができます(設定で切り替え可能)。ただし、get_posts() の場合はデフォルトでは全文検索が無効になっています。有効にするには suppress_filters パラメータに false を指定する必要があります。
get_posts( array(
's' => '-山田 (太郎 OR 花子)',
'suppress_filters' => false,
) );既知の不具合
PDF ファイルのフォーマット形式によっては、テキストが空になる場合と文字化けする場合があります。この場合、PDF ファイルを別の形式で保存するか、別のツールでテキストを抽出して「検索テキスト」項目に貼り付けて対応してください。
gettext empty result · Issue #652 · smalot/pdfparser · GitHub
Strange chararacters while parsing PDF · Issue #654 · smalot/pdfparser · GitHub
公式ディレクトリ
ベータ & RC リリース
| 2.13.1-RC1 | 2023年12月5日 | zip |
更新履歴
| バージョン | 説明 |
|---|---|
| 1.0.0 | 最初のリリース。 |
| 1.1.0 | WordPress マルチサイトにおける、アンインストールのバグを修正しました。 full_text_search_limit フィルターフックを追加しました。 |
| 1.2.0 | InnoDB の場合に、正しく検索されない不具合を修正しました。 |
| 1.3.0 | 全文検索を有効化、無効化するオプションを追加しました。 |
| 1.4.0 | 添付ファイルに対応しました。 |
| 1.4.1 | 投稿タイプの exclude_from_search パラメーターに従うように変更しました。 |
| 1.6.0 | PDF ファイルの検索に対応しました。 |
| 1.6.2 | UI (用語など) を微調整しました。 |
| 1.6.3 | テキストが正しく翻訳されないバグを修正しました。 |
| 1.7.0 | メディア一覧に PDF のテキストの文字数を表示するようにしました。 PDF ファイルの読み込みに失敗した場合の処理を変更しました。 |
| 1.8.0 | メディアファイルに検索テキスト (PDF テキスト) 項目を追加しました。 全文検索用のカスタムフィールド(full_text_search_search_text)を追加しました。 |
| 1.8.2 | 非公開投稿が検索できない場合がある不具合を修正しました。 PDF 自動生成したテキストを検索テキスト項目に表示するように変更しました。 |
| 1.9.0 | 添付ファイルで PDF のみを検索するオプションを追加しました。 |
| 1.9.1 | PDF のみの検索が有効にならない不具合を修正しました。 |
| 2.0.0 | Word (doc、docx) ファイルの検索に対応しました。 |
| 2.1.0 | Excel および PowerPoint ファイルの検索 に対応しました。 |
| 2.2.0 | 設定ページをリニューアルしました。 |
| 2.2.1 | 翻訳テキストの漏れを修正しました。 |
| 2.2.3 | SQL を最適化しました。 |
| 2.2.4 | PDF Parser ライブラリを1.1.0に更新しました。 |
| 2.2.5 | 空の検索結果画面の警告を修正しました。 |
| 2.2.6 | PDF Parser ライブラリを2.0.1に更新しました。 |
| 2.2.7 | 添付ファイルのみの検索の不具合を修正しました。 |
| 2.2.8 | PDF Parser ライブラリを2.1.0に更新しました。 |
| 2.2.9 | PDF Parser ライブラリを2.2.0に更新しました。 |
| 2.2.10 | PDF Parser ライブラリを2.2.1に更新しました。 |
| 2.3.0 | ソート順オプションを追加しました。 |
| 2.4.0 | 検索ページに検索スコアを表示するオプションを追加しました。 |
| 2.4.1 | 検索順の不具合を修正しました。 |
| 2.5.0 | 検索文字列オプションを追加しました。 |
| 2.5.1 | 空の検索でエラーメッセージが表示される場合がある不具合を修正しました。 |
| 2.6.0 | full_text_search_index_post フィルター フックを追加しました。 |
| 2.6.1 | アンインストール時に full_text_search_search_text カスタムフィールドを削除しないで残すように変更しました。 |
| 2.7.0 | パフォーマンスの改善を行いました。 |
| 2.7.1 | データベースのインデックスが再生成されない不具合を修正しました。 |
| 2.7.2 | 検索ページ以外の検索ができない不具合を修正しました。 |
| 2.8.0 | パフォーマンスの改善を行いました。 PDF のテキスト自動抽出から、空白や改行などの制御文字を削除するように変更しました。 |
| 2.8.1 | すべての添付ファイルから検索テキストを削除する機能を追加しました。 |
| 2.9.0 | 検索結果ページの検索キーワードをハイライトする機能を追加しました。 SQL を最適化しました。 |
| 2.9.2 | 全文検索の対象を exclude_from_search の投稿のみに変更しました。 インデックスの再生成時に、添付ファイルのテキストが抽出されない不具合を修正しました。 |
| 2.9.3 | デフォルトの設定値を変更しました。 セキュリティを強化するために、複数の翻訳テキストにエスケープ処理を追加しました。 |
| 2.9.4 | PDF Parser ライブラリを2.2.2に更新しました。 full_text_search_pdf_text フィルターフックを追加しました。 |
| 2.10.0 | ショートコードの内容を検索するオプションを追加しました。 再利用ブロックの内容を検索するオプションを追加しました。 HTML タグを検索するオプションを追加しました。 PDF Parser ライブラリを2.3.0に更新しました。 |
| 2.10.2 | PDF から抽出したテキストに含まれる制御文字を削除するように変更しました。 検索キーワードをハイライトするタグを調整しました。 |
| 2.11.0 | mark.js を使用しないように変更しました。 |
| 2.12.0 | PDF Parser ライブラリを2.4.0に更新しました。 WordPress PHP コーディング標準に準拠するためのコード リファクタリングをしました。 |
| 2.12.1 | Composer autoloader を Jetpack autoloader に置き換えました。 |
| 2.12.2 | PDF Parser ライブラリを2.7.0に更新しました。 |
| 2.12.3 | 管理画面の投稿一覧ページのタイトルが文字化けする場合がある不具合を修正しました。 |
| 2.12.4 | 検索キーワードのハイライト表示の不具合を修正しました。 「再利用ブロック」の名称を「同期パターン」に変更しました。 |
| 2.13.0 | WordPress バージョン 6.4 に対応しました。 |
| 2.13.1-RC1 | PDF Parser ライブラリを2.8.0-RC2に更新しました。 |
| 2.14.0 | 検索キーワードのハイライトに mark.js を使用するオプションを追加しました。 WordPress coding standards 3.0.1に準拠するようにリファクタリングしました。 |
| 2.14.1 | PDF ファイルのテキスト抽出時にエラーが発生する不具合を修正しました。 |
| 2.14.2 | PDF Parser ライブラリを2.8.0に更新しました。 |
| 2.14.3 | WordPress バージョン 6.5 および MySQL バージョン 8.3 に対応しました。 PDF Parser ライブラリを2.9.0に更新しました。 |
| 2.14.4 | 一部のプラグインとの互換性の問題を修正しました。 |